
Web Performance Testing with Visual Studio Ultimate 2013 Part 2
Part 2 – Validation Rules, Extraction Rules, and Coded Web Tests
Note: The code used below can be found on GitHub at https://github.com/kevin-tuttle/Contoso-FAS-Testing.
In my last post – Part 1 – I discussed how to use the Microsoft Web Test Recorder and other wizards to build a Web Performance Test. The test would load a webpage with a form on it, complete the form with static data, and then store the returned data for review. This was useful for reviewing the overall process, and if your goal is to simply confirm that the page exists and that the form submits, it’s a good test to run. But, if you want any kind of benchmarking, or to confirm that the form is actually submitting correctly, it’s still inadequate. For the real test, I’ll need to add some Validation Rules.
Validation Rules
Validation Rules do exactly that – given specified criteria, the rules either pass or fail based on the data that is returned during the testing process. If you’ve written other test types, like Unit Tests or Integration Tests, it’s the same idea. You’re ensuring that things went the way you expected them to.
To demonstrate how they work, I have built an extremely basic form with only three fields: first name, last name, and email address. The form is a GET form so when it submits it will just put the data into the query string. The page also takes any data that’s in the query string and adds it to the HTML on the page itself.


You can see in the “after” screenshot that the data has been placed into the query string and the HTML itself, below the buttons. It’s an overly-simplistic setup, but we can use it to build some validation rules and see what they are capable of.
Like before, I used the Web Test Recorder to capture the network traffic and trimmed out some of the unneeded transactions. I’m left with two different requests – the initial page load, and then the same page again with the values in the query string.

Now that those requests are in place, I’m ready to setup some validation rules. The first test that I want to do is ensure that, when the page is loaded without the data in the query string, the labels at the bottom don’t have any values. Like so:

To do that, I’ll add a Validation Rule to check the page HTML and see if it contains the string First: </br>. If it does, then I know that there’s no text on that line after the First label.

There are many of out-of-the-box types to choose from; in this instance I’m going to use the “Find Text” rule which, as the name implies, simply checks the response content for a particular string. This will demonstrate the simplest way to extract content from the page itself. If this were a real test, where I could set the page to contain whatever I wanted, a better practice would be to put the data to be examined inside of a markup tag of some kind. That would be more precise and cleaner than doing a straight string search. But if you’re building tests based off of content someone else has written, you might not have that option.
Of the other rule formats available, they generally they fall into one of two categories: There are those that check the content itself, which includes making sure a particular form option is selected, a specific tag exists somewhere in the response, or that a particular field has a specific value. Then there are generic page-level rules such as one that checks the response time of the page and one to confirm the URL of the response page.

Here I can specify the options for the rule – the properties available vary based on what the rule requires. The options for the Find Text rule are pretty straightforward: I’m just going to put the text to find in the “Find Text” property and then leave the rest at defaults.

I’ll go ahead and add similar rules to cover the last name and email address fields as well. As before, the only property that needs to be set is the “Find Text” property. Once those are setup I can click the Run Test button to see if the Validation Rules are working.
When these tests are run it is run in what’s called a “headless browser” – that is, it doesn’t really have all of the added functionality (and overhead) of running the same kind of operations inside a standard browser. Instead, it’s basically just straight HTTP requests and responses. This makes it very fast, and suitable for high-volume load testing, but does not allow for any kind of rules involving client-side scripting execution, or non-HTML based entities such as ActiveX controls or Flash objects. Some of these can be simulated, with some effort, if needed, but it doesn’t work right out of the box.
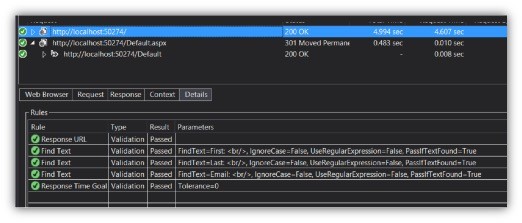
Here are the results of the test. For each one, you can see that the Validation Rule was executed, the text extracted, and found to match the specified string.
Because those tests passed, we know that that the initial page contains those three strings, which means it does not contain any data yet, and thus that the page is rendering as I expect. But, what if I wanted to retrieve some of the data and store it in a variable for use later? For that I’ll need an Extraction Rule.
Extraction Rules
Extraction Rules work very similarly to Validation Rules in that you add them to a particular web request, set the options, and then it gets integrated into the testing process. A lot of the rules are the same as well, the only difference being instead of simply confirming that some criterion is met, it retrieves the data from the response and then stores it in a local variable.
To do this, the test has, what is in effect a global Dictionary (Dictionary<string, object>) called Context. It is really its own class WebTestContext that implements IDictionary and adds on a few class-specific properties like AgentName, WebTestIteration, etc. which are useful when it comes to load testing. An Extraction Rule can take data out of the response and then add it to the Context with a given Key. It can then be retrieved later and used for things like changing the flow of the test (branching or even repeating) and of course a lot more when it comes to the coded version.
Just like the Validation Rules, you can add an Extraction Rule by right-clicking on the web request with the response from which you want to parse the data.

Selecting that gives you different kinds of Extraction Rules. Like before, this is just different ways of identifying the data to be parsed out. Some of the rule types include:
- Selected Option – Given a particular select tag’s ID value, this extracts the selected option’s text value
- Tag Inner Text – Given a particular tag, with a given attribute name/value pair, this extracts the internal HTML from the tag
- Extract Form Field – Given a form field name, extract the field’s value
- Extract HTTP Header – Given a header name, extract the header’s value
- Extract Regular Expression – Given a regular expression, extract the indicated value – this is particularly useful for quick-parsing of JSON objects
The one I’m going to use for this rule is just “Extract Text.” It takes a string for the “start” and one for the “end” and then just returns anything between the two. Obviously you’ll want to ensure that both of these are unique to the entire response document, but it is otherwise a very powerful rule type. I use it later for basic JSON parsing, but in this instance I’ll just use First: for the start field and <br/> for the end.

This rule will extract any HTML between those two strings and store it in the Context object with the FirstName key. It’ll be accessible, as in any other Dictionary, with Context[“FirstName”].
Obviously, doing a straight extraction based on “start” and “end” strings like this isn’t necessarily the most ideal situation. If you have control over the actual HTML itself then you’d want to put the data into a header, or by itself in a uniquely-identified tag like: <div id=”firstNameResult”>Kevin</div> in which case you’d use a Tag Inner Text rule and could be sure that there wouldn’t be any false positive matches. I’ve found that you don’t usually get that much control over what is being validated or extracted, , so I’m going to use the basic rule for this and then do the same thing for LastName and Email. I’ll also add some Validation Rules, just like before, to this request to ensure that the returned HTML includes the strings First: Kevin<br/>, Last: Tuttle<br/>, and Email: ktuttle@ivision.com<br/> the only difference is that this time the data is populated.
This is what the list of requests and rules looks like now:

As before, we can run the test to confirm that the form process is running as expected:

You can see, in this list, where the three Validation Rules have passed, finding the submitted data in the returned HTML. Also, the Extraction Rules ran successfully and extracted the data into the Context object. If you click on the Context tab it will show all of the data in that object at the time of that particular request. Here we can see in this list, along with other automatically-added variables, the three custom values that we wanted to extract from the HTML:

Pretty straightforward, right? Now where this is really helpful is when you’re running a series of tests whereby you need to be able to change the requests based on the results of previous requests. There will be a lot more of this later, but for now just think of a website that makes a series of web service calls based on user interaction with the controls. Being a headless browser, there’s no way to do the “clicking”, of course, but if the activity that happens because of that click is a web service call then that can be simulated.
So, imagine that one of the fields on the website is a text field to type in a stock market ticker symbol. When the user types in the symbol, it retrieves the current price for that stock from a third-party source, and then passes that value, with the ticker symbol, into a custom web service that checks to see how many shares to buy or sell. When the user does this it’s all handled behind the scenes by the scripting, but that won’t work here. What you would have to do is pass a given stock symbol (say, one determined at design time) into the third-party service, and then save what it returns into a Context variable. Then, in the next step, take that same value, with the symbol, and pass it into the customized service.
Basically, any time that a step in the test needs information from the result of a previous test, it will be useful to just store it in the Context object.
Now that we have a handle on the process in general, we can look behind the curtain and see what the actual code looks like. To do that, simply click the Generate Code button, and give the new class a new name:


This will leave your previous test intact and just create a new class that does exactly the same thing, but in code so that you can see how it works.
The first thing it creates, of course, is the class declaration and a basic constructor. Note that all of these inherit from the Microsoft.VisualStudio.TestTools.WebTesting.WebTest class. The key part of the class is the abstract function IEnumerator<WebTestRequest> GetRequestEnumerator() which is the main “engine” of the test itself.
When the test is run, it will call GetRequestEnumerator and then, as might be expected, iterate through every one of the returned WebTestRequest objects and execute them. All of the requests are in there with their various rules attached and they just execute in order. This is what our generated override version looks like:

The first thing it does is initialize the test-wide Validation Rules that were at the bottom of the previous version. These rules apply to every request and allow you to make sure no single request takes longer than a given time to run, or that the response URL is a particular value. After those are setup it runs our first web request:
![]()
That’s it – that’s the web request. Of course the first one was pretty simple: just load the requested page. The web request, has an event called ValidateReponse that is called after the response is received. The way that the Validation and Extraction Rules is to subscribe to that event. Here’s the request again with its subscribed Validation Rules:

Breaking that down, you can see where each Validation Rule is declared as its own object: validationRule3, validationRule4, and validationRule5 (I probably had some others earlier and deleted them – normally it would start with “1”). Each rule instantiates itself as being a ValidationRuleFindText (each rule type has its own class with specific properties and such that inherit from ValidationRule), sets its particular properties, and then subscribes itself to the ValidateResponse event on request1.
The if block that’s surrounding it is something I haven’t mentioned yet, but basically, for each rule, you can assign a ValidationLevel (an enum of Low, Medium, and High) which is similar to “severity” in logging and event-tracking systems. You can specify the importance of that particular validation and then, when building more complex tests like in load testing, modify which rules are run and how to handle exceptions to them based on this validation level. Since the tests I was running required everything to work without fail, I didn’t use them very much, but for regular, automated tests it could be helpful.
Lastly, since the function is returning an enumerator, the request is finished with yield return, which returns the request to the enumerator and then continues on with the execution.
The second request is a little more complicated because of the query string, but not much:

The Validation Rules are unchanged except for the text now including the expected values. The first new thing is the ExpectedResponseUrl property, which can be used to validate that the returned URL matches what it’s expected to be. This property is used by that global Validation Rule from earlier. If that rule is disabled then it’s just ignored.
There’s also code there to build the query string using the QueryStringParameterCollection QueryStringParameters property. You might reasonably ask why it is that we have to build that collection at all since it was submitted in the form in the previous page. That page, having a GET form in it, should have returned the URL with all of that already populated. But it’s important to note that HTTP requests in general, and automated testing in particular, are fairly stateless.
The goal is to simulate the requests and most of the time there won’t be the back-and-forth of normal web usage. There’s no way, using the headless browser, to do a “submit” on the form. The submission of the form is a client-side operation, and there’s no way, using server web requests, to properly do it. So, all we can do is simulate the results of the submission, which is the request with the query string parameters. A form using POST would work the same way, the only difference being that the second request would have to include the field data in the headers instead of the URL.
This second request, besides having all of the Validation Rules attached to it, also has our three Extraction Rules attached, with the same event subscription model, using the ExtractValues event.

Just like with the Validation Rules, it creates the object (using, in this case, the ExtractText class, which derives from ExtractionRule), sets its parameters, and then subscribes its Extract property to the requests’s ExtractValues event. Finally, request2 is returned with yield and set to null.
And that’s all there is to it – all the guts that make up the rule we’ve created using the wizard. Now if you’re anything like me, you may be looking at that code, with its almost identical code execution, extraneous object declarations, and hardcoded values, and die a little inside. And that’s ok – in the next part I’m going to go over how I took this code and abstracted it out into (what I think is) a much cleaner and reusable format that uses a database to automatically build both the requests and all their rules automatically.


